The Awesense SQL API is so easy to work with, ChatGPT can do it!
Ease-of-use is one of the guiding lights we follow for the development of the Awesense SQL API. In addition to its simple structure, we’ve also accompanied it with documentation, tutorials, and sample code implementations to make it as quick as possible for our users to develop use cases on top of it. See the testimonials from students in the 2023 PIMS M2PI program for how easy it was!
What could make it even easier? The use of ChatGPT!
With the rise of large language models (LLMs)’ usage as coding helpers, we decided to test whether we could get OpenAI’s ChatGPT to understand our SQL API and write code using it. Tldr: test successful! Below is an account of our step-by-step experience.
We have used GPT-4 (offered as part of the ChatGPT Plus subscription), as it performs better on coding tasks than GPT-3.5 (See Sparks of Artificial General Intelligence: Early experiments with GPT-4). If trying to reproduce this yourself with your own ChatGPT account, please note that you may not get exactly the same results, as its output is not deterministic; when working with ChatGPT to produce this post, we got different answers to the same question on different days. We employed neither plugins nor the Code Interpreter feature (recently rebranded as Advanced Data Analysis). Because our SQL API is very compact, we could simply copy and paste it into the GPT-4 prompt box. (Note: our SQL API documentation is available from our Sandbox environment. Check out the free trial we’re currently offering for the Sandbox.) We told ChatGPT to read it and prepare to be asked to write some SQL queries using it. The documentation still spans a couple of pages, so here are screenshots of the beginning and end of it as provided to ChatGPT:
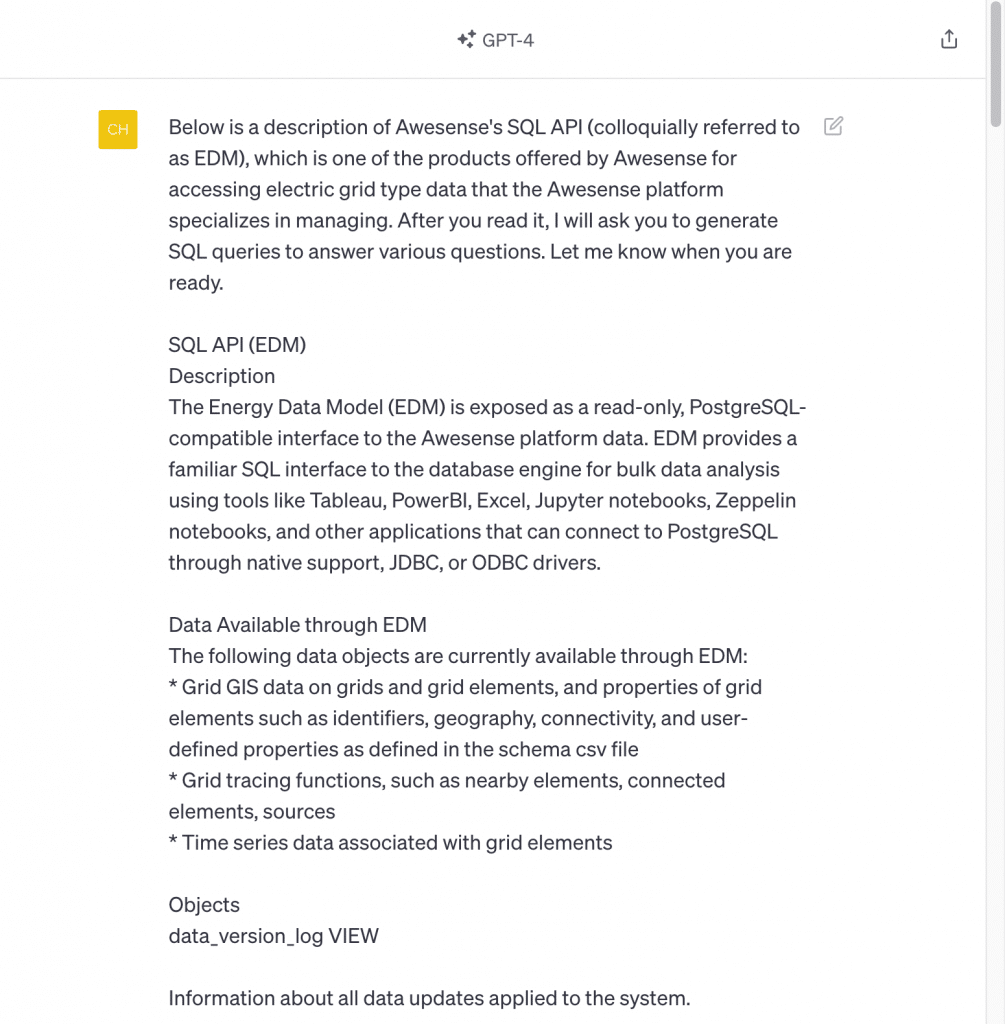
…

Ok, it seems pretty confident it can help – but then again, it always projects confidence, even when it is wrong. So we asked it to summarize what it learned:

It came back with 7 bullet points (screenshots truncated due to length), most of which just provided verbatim bits from the preamble of the documentation text we gave it. But bullet points 5 & 6 (see below) do actually summarize well the contents of the API definition itself, and the final paragraph on what the API is for is pretty spot on.

So, let’s say we’re a new user who would like to connect to the SQL API from Jupyter notebooks. Where do we start? Let’s ask:
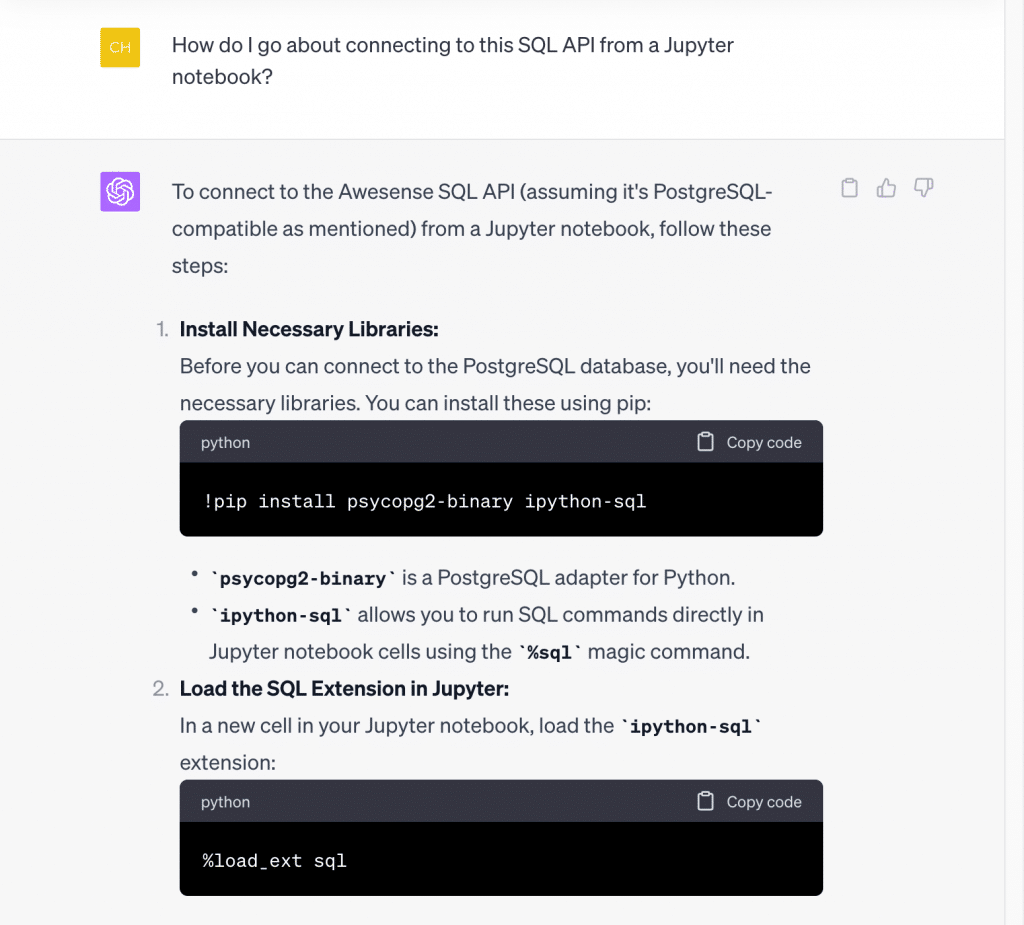
…
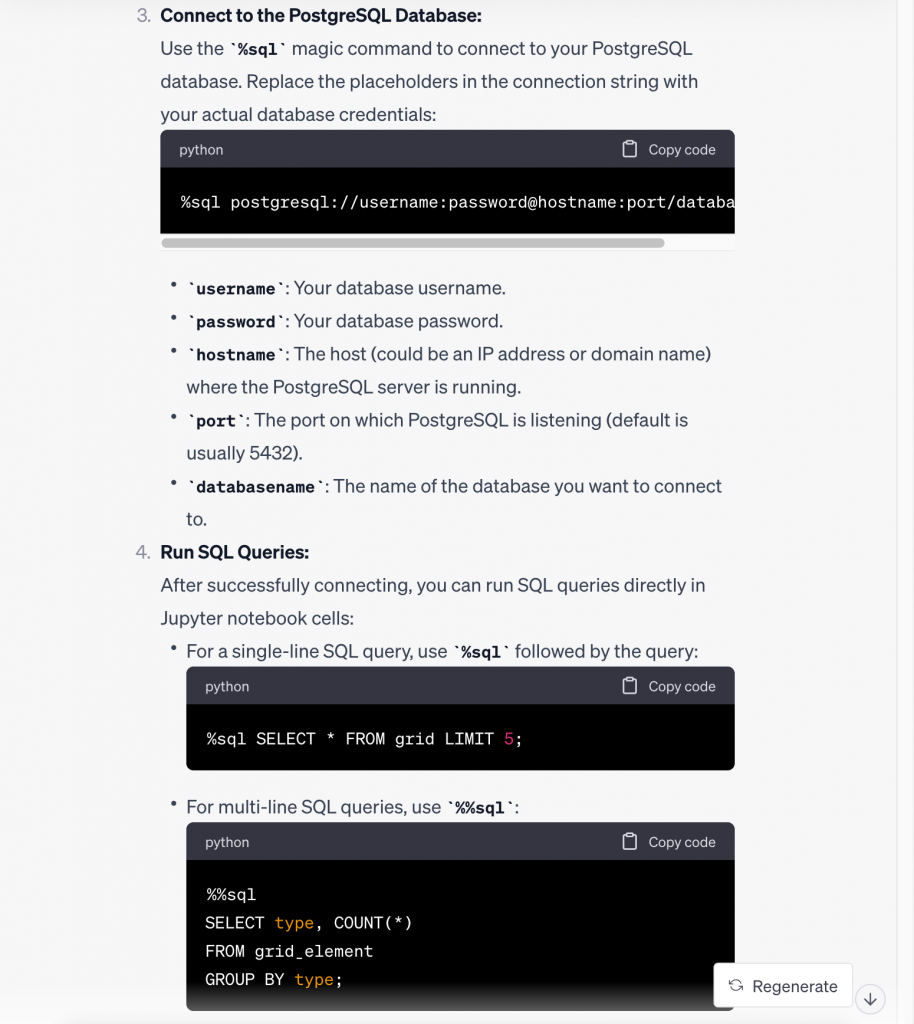
…

That is a very good step-by-step answer. It is roughly in line with what we teach in our introductory tutorial notebooks that we make available as part of the GitHub repo we provide access to with the Sandbox subscription. And a nice note at the end about security: our tutorial notebooks show you how to deal with credentials safely.
It also already provided some examples of queries using API views like grid and grid_element, but let’s ask it more explicitly what queries we should run first to get the hang of the Awesense SQL API:
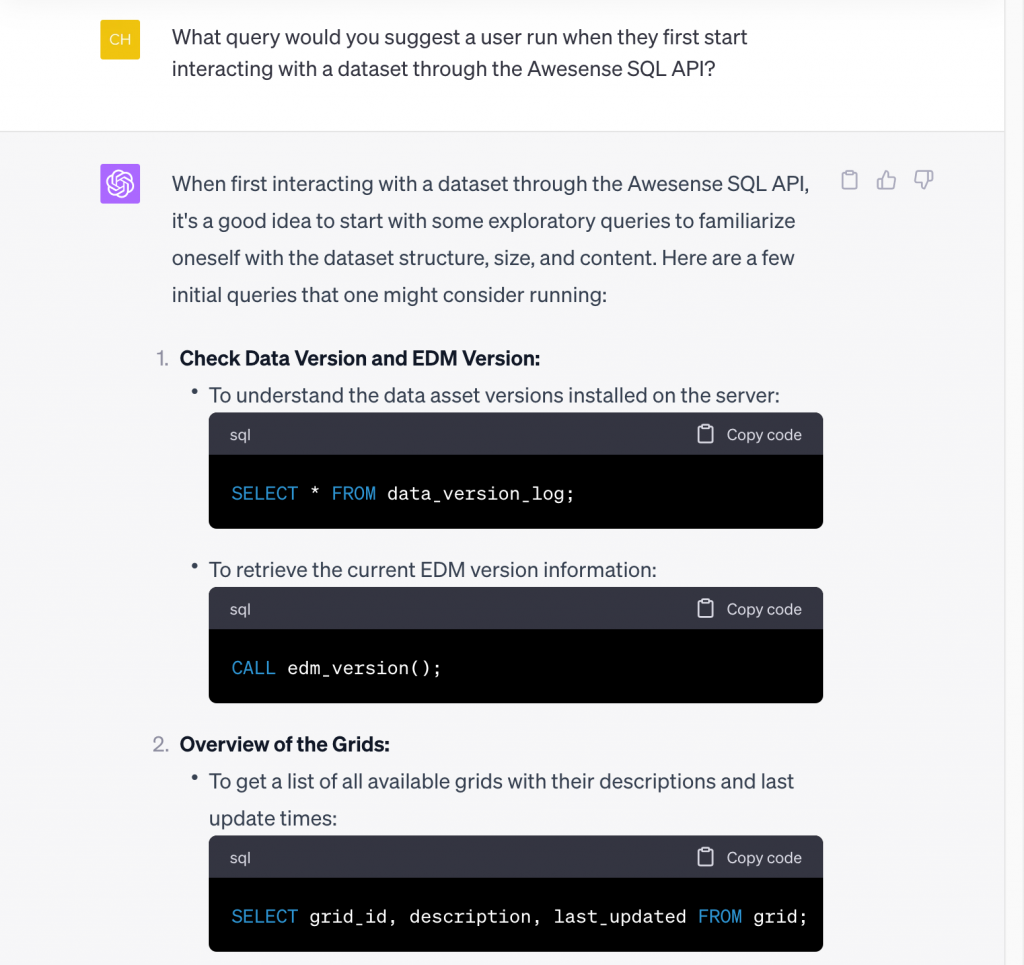
…

Great suggestions! So, we opened up a Jupyter notebook and established a connection to the sandbox server. Here is a screenshot of the output of the get-all-grids query it suggested (item 2 above):

As we can see, this dataset contains a single grid called ‘awefice’ (get it?). Let’s tell ChatGPT that and ask it for further assistance. We will then copy the queries it suggests, paste them into the Jupyter Notebook, and run them. We start by asking ChatGPT for help counting how many transformers there are in the ‘awefice’ grid:
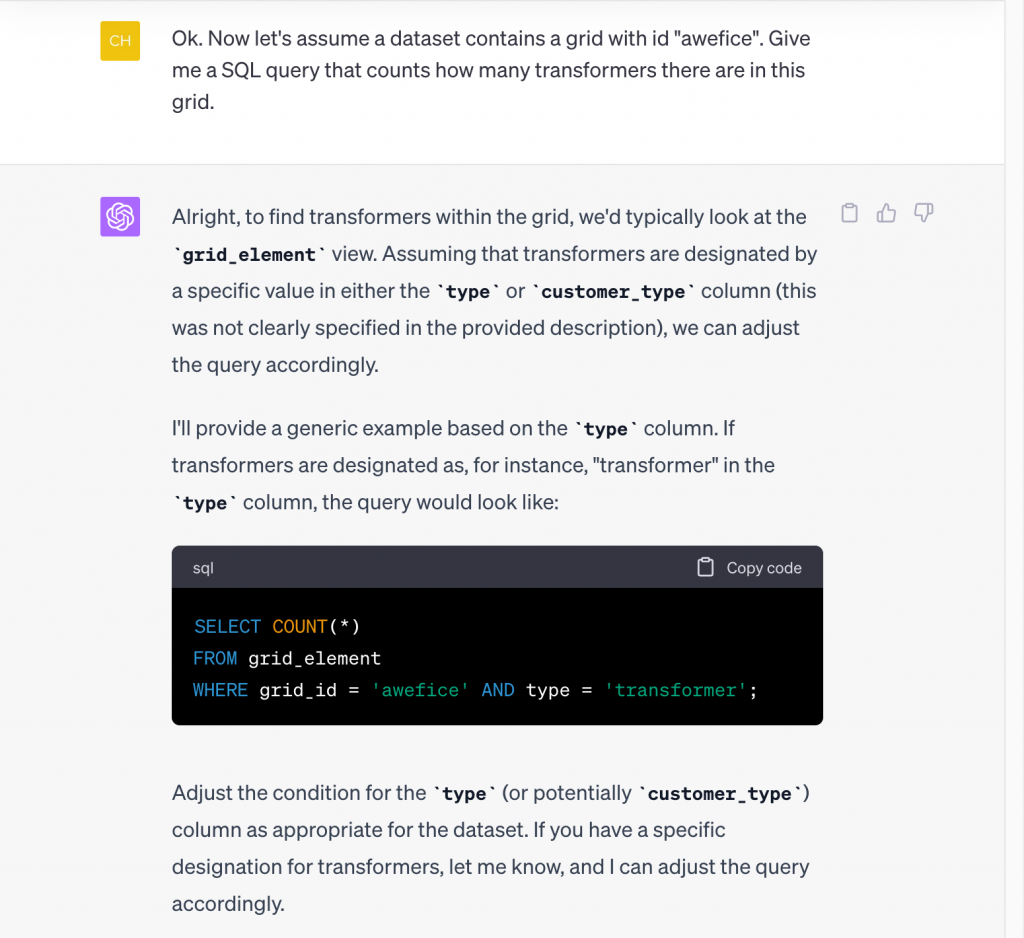
When run in Jupyter, the suggested query returned 0 results, but as ChatGPT suggested, it may just need adjusting the designation for transformers. We ask ChatGPT to help us determine the right designation from the data, namely what type of grid elements there are:
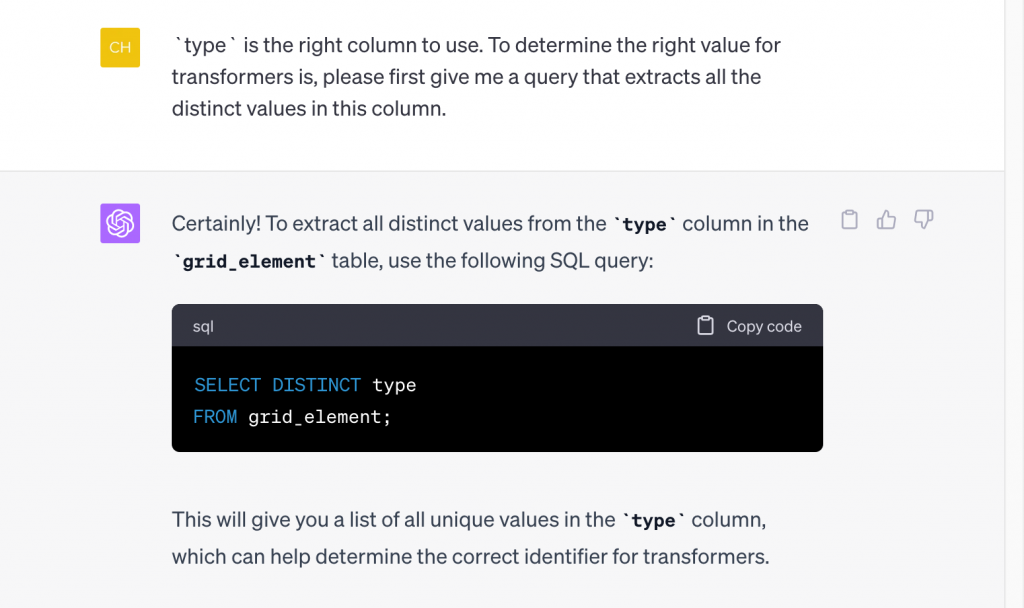
Here’s the output of running the suggested query:
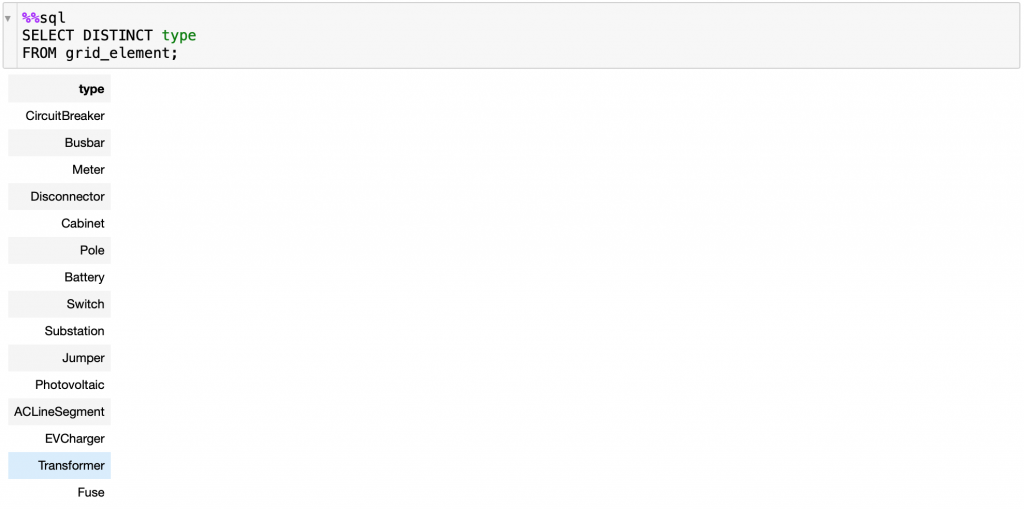
It seems it’s just a capitalization issue. We could fix it ourselves, but we decided to let ChatGPT know about it as well for future reference and asked it to adjust the query for us:
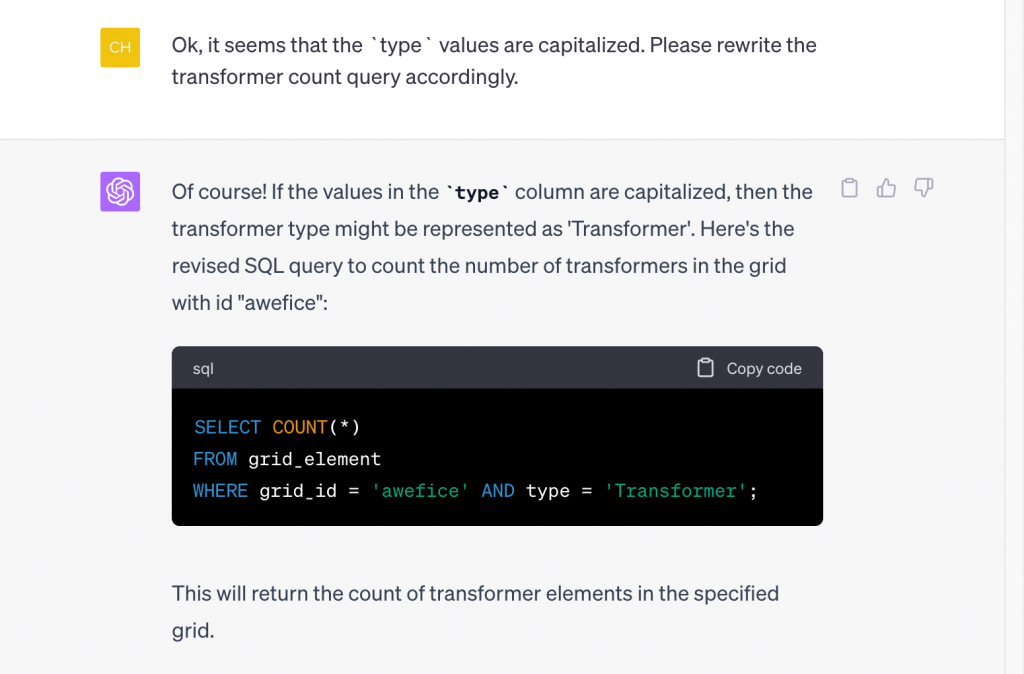
Running this updated query (output below), we can see now that there are 10 transformers in the ‘awefice’ grid in this dataset. (Note: For the purpose of this blogpost, we have connected to the tier 1 offering of our Sandbox environment, which contains a small grid; the tier 2 & 3 offerings contain a larger grid with hundreds of thousands of grid elements.)

Let’s continue! We use a very sparse request for ChatGPT to do “the same” for Meters:
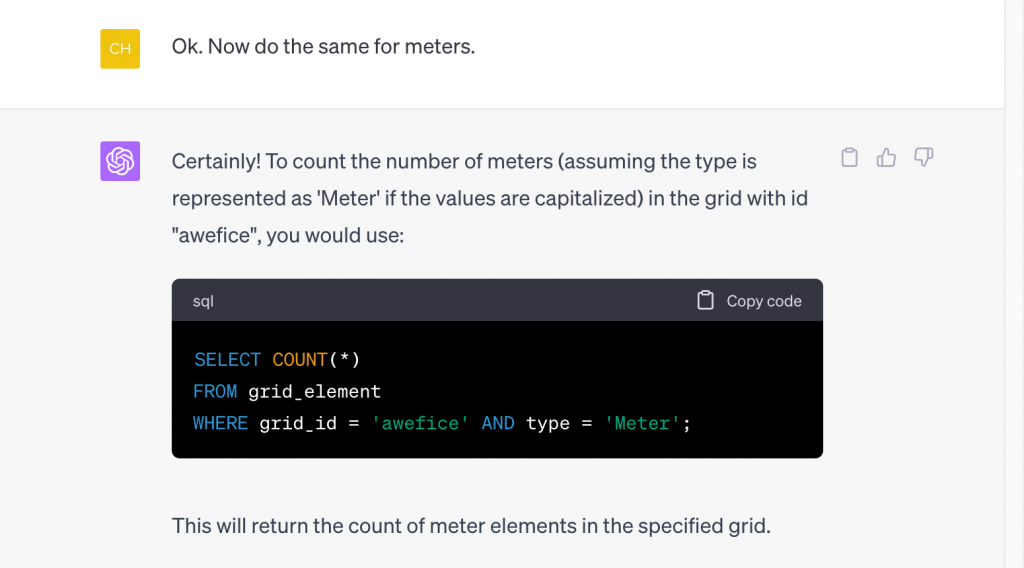
It understood that by “the same” we meant counting meters and the query it gave us showed upon running that there are 27 meters in the ‘awefice’ grid:

Next we up the level of complexity. So far ChatGPT only had to do simple selecting out of the views in the SQL API. Let’s see if it can figure out how to use some of the functions that the API comes with. We ask it for something that we know requires applying an operation that traces through the network structure, but a new user of the API might not. Specifically, we ask how many meters there are downstream of each transformer:
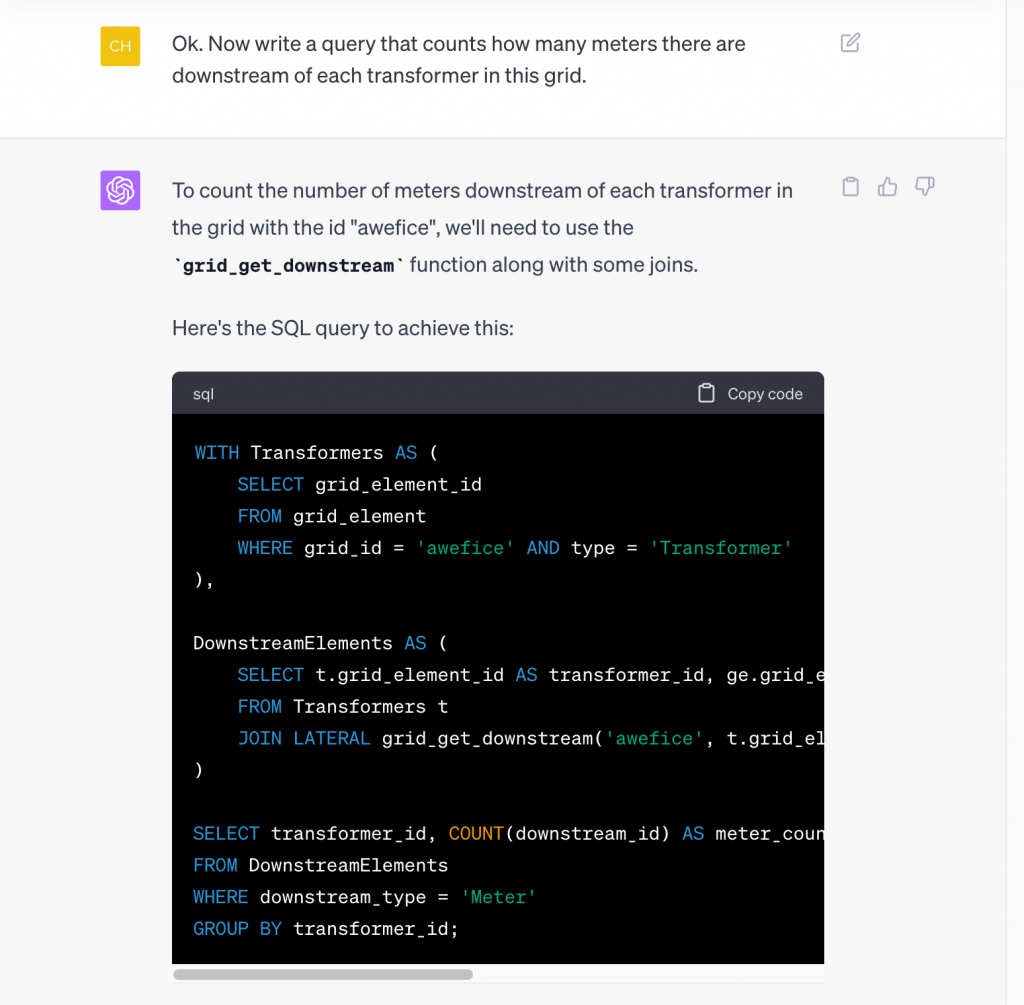
…

That is a really long query! It did come with an explanation of how it works, and it does actually produce the correct output when run, but let’s ask ChatGPT to simplify it:
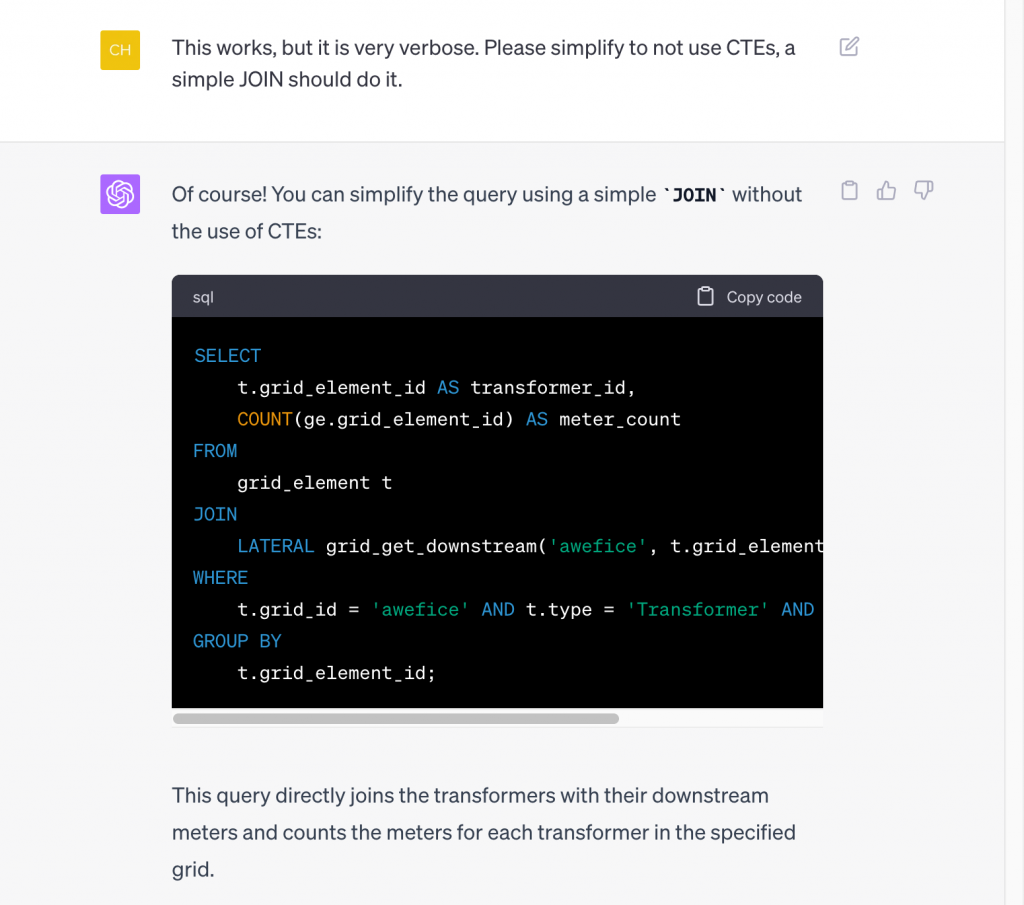
Note that we asked it to not use CTEs (a SQL construct known as a “common table expression”) without explaining to it what that is, nonetheless, it produced a much simpler query without CTEs (albeit using more newlines, which on the surface make it still look rather long). Below is the output of running it:
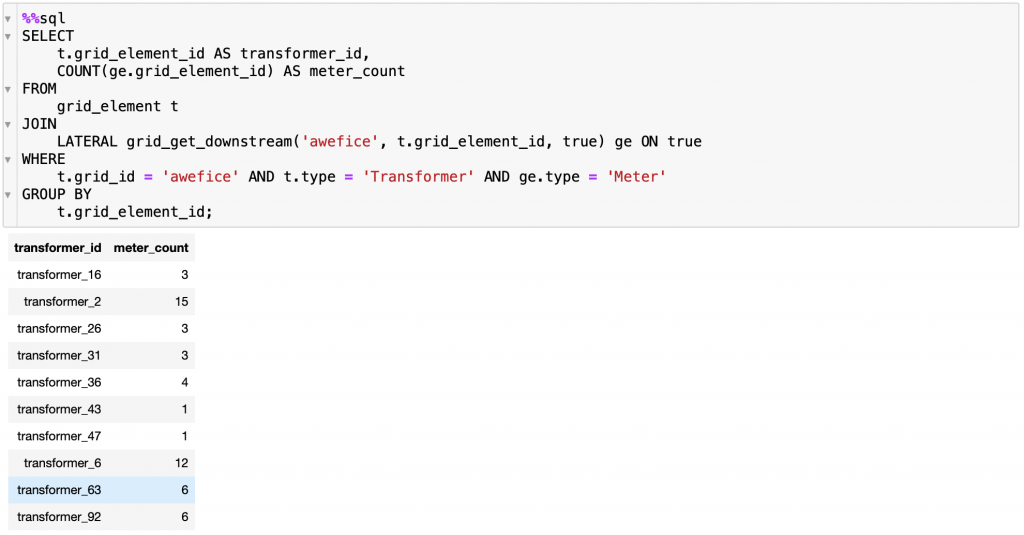
Great! How about trying to retrieve some time series on top of performing tracing? We ask ChatGPT to sum up the time series retrieved from meters up to the transformer level:

…
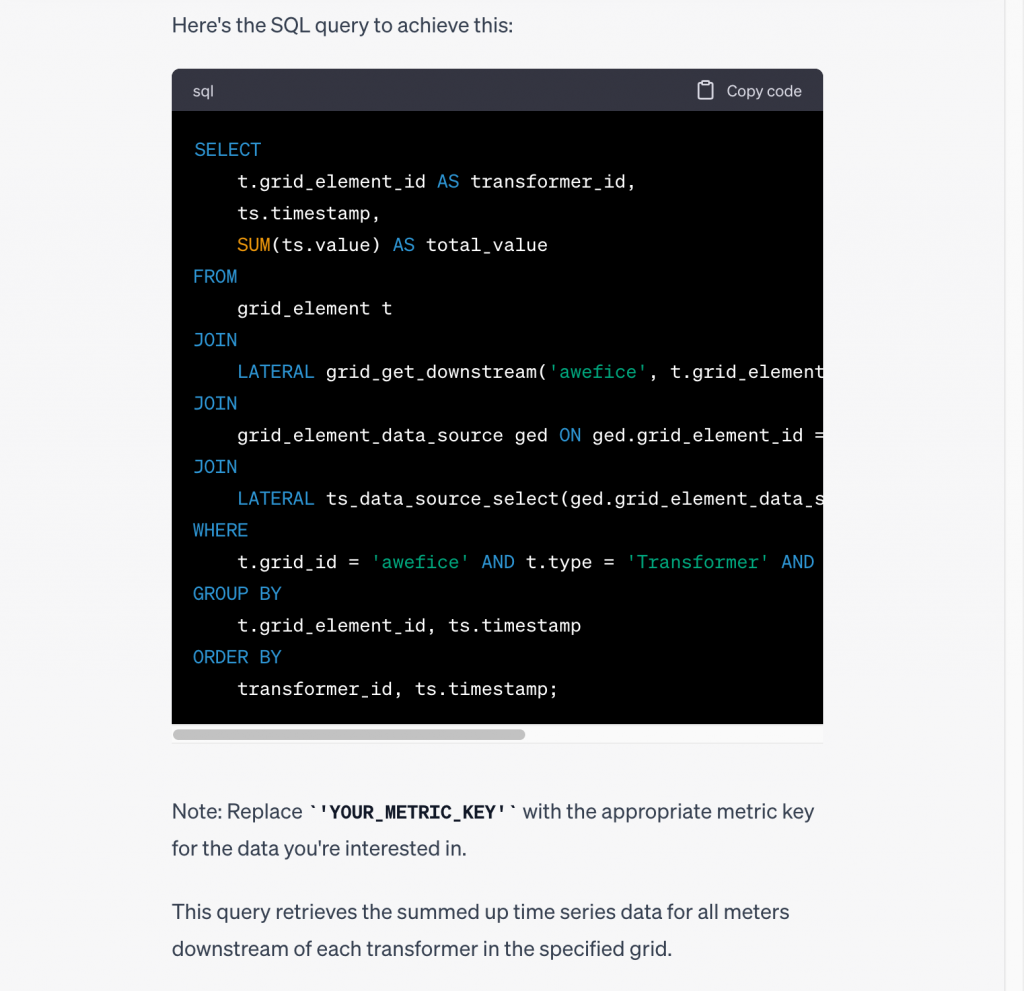
Not bad, ChatGPT! That is a correct, non-trivial piece of code it just wrote, figuring out how to combine a tracing function with a time series retrieval function. And it also told us that we need to ask for a specific metric (we happen to know that meters have a ‘kWh’ metric, but you could try actually asking ChatGPT to figure out from the data what metrics are available – let us know how that goes!). This kind of query actually retrieves a lot of data, so instead of viewing that in text form, let’s also get ChatGPT to bring the data into Python and help us visualize it in a chart. We do this using a sequence of two requests (first to use ‘kWh’ and Python, then to chart):
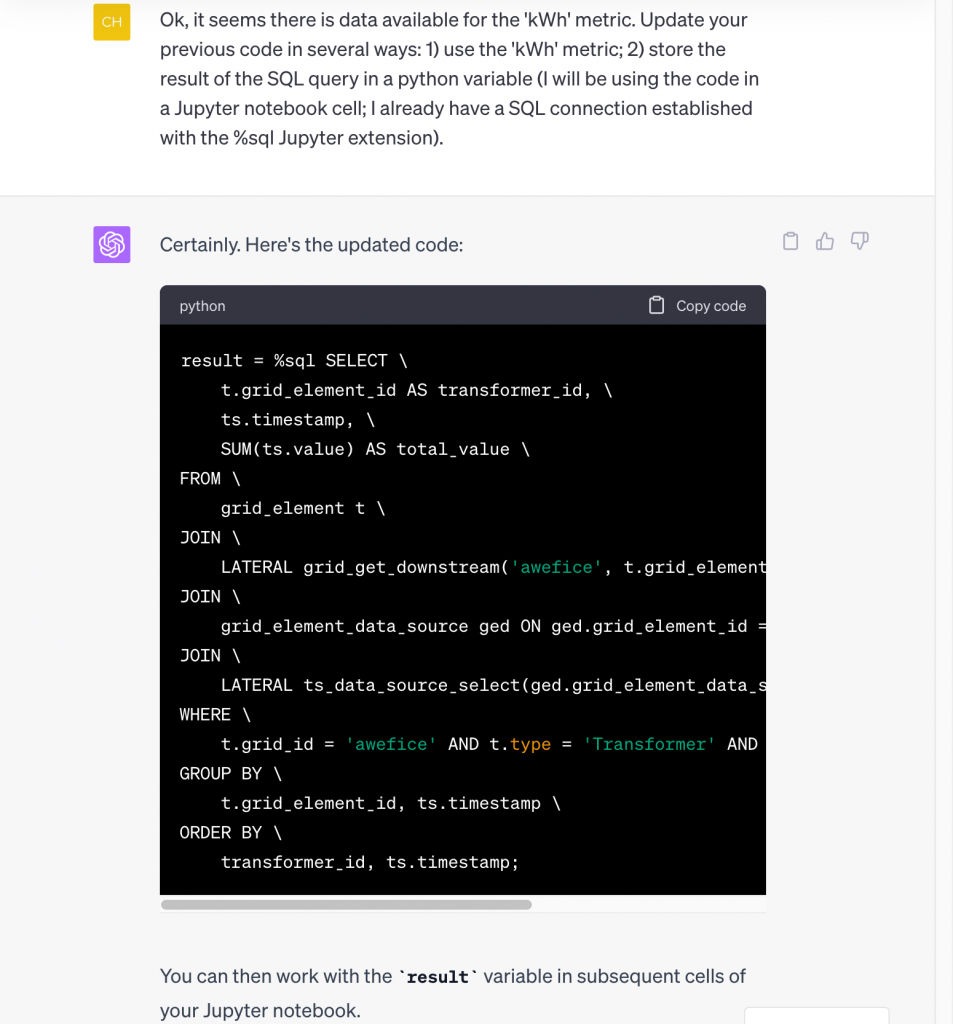
…
And here are the results of running the code it generated:

…
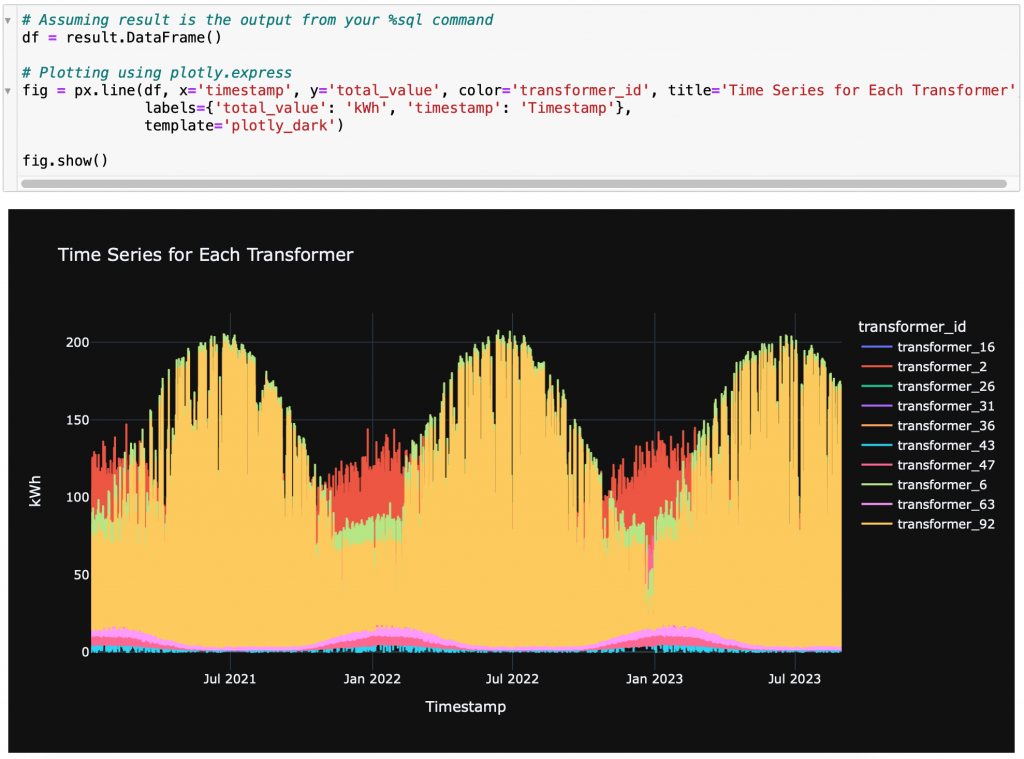
There you have it: from zero knowledge about our APIs to an actual chart – and a lot of learning along the way – in (almost) no time! Of course, we still encourage users of our APIs to go through our GitHub tutorials to get a deeper understanding, and the complete documentation is available to consult when details are needed. But thanks to LLMs like ChatGPT, the actual writing of code can be much faster, and more effort can be dedicated to deciding the meaningful analyses. All of it is on top of the fact that the Awesense platform already brings all the data under one roof in a coherent data model exposed through APIs, and the time required to build use cases like the ones in our library has dropped by at least one order of magnitude.
Anyway, that is it for now! We hope you enjoyed this blog, and if you have any questions, please do not hesitate to contact us! If you have an idea for a Use Case you’d like to use, please let us know. You can also try our platform with our mentioned Sandbox Free Trial.