Welcome to the sixth installment of the Learn to Build Better series. This multi-part series showcases the tools and techniques to rapidly build, test, and prototype energy-focused applications, analytics and use cases on the Awesense Energy Transition Platform, using the AI Data Engine to process data, and TGI or APIs to access and visualize the data structured according to the Awesense open Energy Data Model (EDM). In this episode specifically, we will focus on an analytics service from Microsoft: Azure Synapse Analytics.
What is Azure Synapse Analytics, and why do we use them?
Azure Synapse Analytics is positioned as an all-in-one analytics service, encompassing storage and analysis of data warehouses and big data. Microsoft’s description is “Azure Synapse is an enterprise analytics service that accelerates time to insight across data warehouses and big data systems. Azure Synapse brings together the best of SQL technologies used in enterprise data warehousing, Spark technologies used for big data, Data Explorer for log and time series analytics, Pipelines for data integration and ETL/ELT, and deep integration with other Azure services such as Power BI, CosmosDB, and AzureML.”
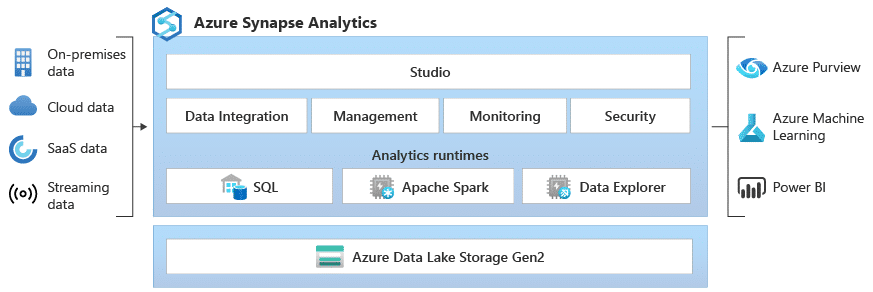
In this blog post article, we will focus on the data analytics aspect of Azure Synapse Analytics in Synapse Studio. We will demonstrate how features of Synapse Studio can be used for delivering impactful analytics leveraging the capabilities of Awesense’s Energy Data Model (EDM).
What is Synapse Studio for?
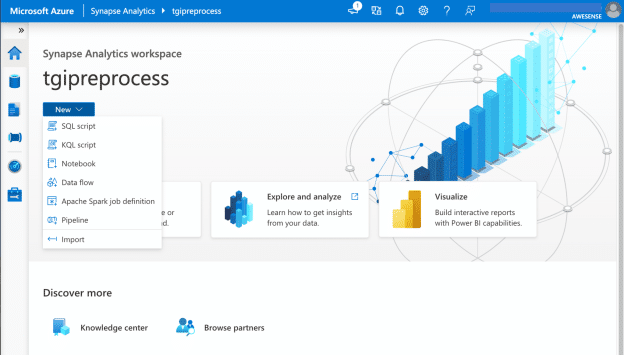
Synapse Studio is the entry point to working with Synapse workspaces, which are collections of tools and data. The main options are creating SQL and KQL scripts, notebooks, data flows, Spark jobs, and pipelines.
Synapse Notebooks
Synapse notebooks are part of the “Develop” tools provided by the Synapse workspace. These notebooks can support various development languages such as PySpark, Spark (Scala), .NET Spark (C#) and Spark SQL. They are similar in functionality to Jupyter notebooks and have some interoperability with Jupyter. Any existing Awesense Jupyter notebook .ipynb files (available from the Awesense GitHub repo upon joining the Awesense sandbox program) can be imported directly into Synapse. Below is an example of a notebook run from Azure Synapse against the data in Awesense’s EDM.
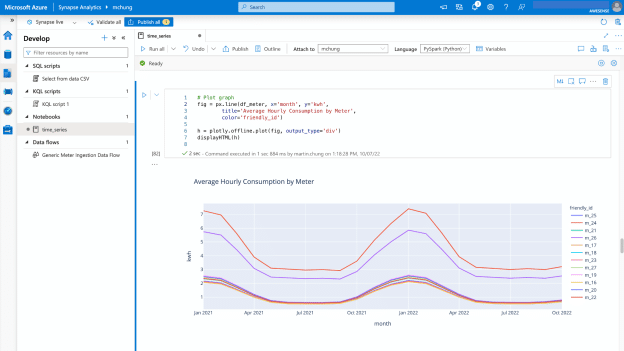
Making Awesense Notebooks Work on Azure Synapse
Awesense Notebooks will need minor modifications to run on Azure Synapse. The standard notebooks use the %%sql magic syntax (SQL Magic extension) to access the <host>-edm.awesense.com EDM database. The SQL Magic extension helps to hide database access code in the notebook.
As SQL Magic is not available on Azure Synapse, Spark JDBC database code wrappers can simply be substituted for the SQL magic commands. The following example shows code that runs an existing query to read the contents of the EDM grid table into a Spark dataframe:

Further Azure Synapse Features
Azure Synapse has some additional features relevant to analytics and data engineering on electrical utility data; for example:
- Azure Data Explorer – stand-alone, fast, and highly scalable data exploration service for log and telemetry data. In some ways, it resembles pgAdmin or other SQL query tools with a set of data sources, a query window, and the ability to export data. Azure Synapse Data Explorer is an implementation of Azure Data Explorer for Azure Synapse. With this tool, browsing, exploring and analyzing time-series data (like, for example, SCADA or AMI data) can be much faster.
- Pipelines – a data integration service that allows you to create, schedule and manage data flow pipelines to move and transform data from various sources to various destinations. It also provides a rich set of data transformation activities, connectors and a web-based user interface for building, scheduling and monitoring data pipelines. This can be used, for instance, to push data into the Awesense platform using our ingestion REST APIs. It can also be helpful if utility data needs to be combined with some external data to address some specific use case.
- Azure Synapse Apache Spark jobs – a job that allows users to use the Apache Spark framework to process and analyze large amounts of data in parallel, allowing for big data processing tasks such as data transformation and machine learning. It can be easily created, scheduled and managed using a web-based interface or code-based development using Azure Data Factory. It is a useful option for analysis or pipelines with large datasets, making them faster.
Next Time, on the Awesense Build Better Series…
The Geospatial Information System (GIS) tools are next for episode seven of the Build Better series. What are GIS tools? You’ll have to wait to find out! We hope you enjoy this Learn to Building Better series, and we hope you continue to follow along. Stay tuned for Episode seven in our Build Better series, focusing on Geospatial Information System (GIS) Tools. You’ll find out how best to tackle efficiently using your GIS data and gather the insights you need to step into the future of data using the Awesense Energy Transition Platform.
Free For a Chat?
We love to connect with fellow data nerds and would love for you to share our content! Follow along with this series, and let us know what ideas you would like to see us write about next.
If you or your team are interested in building a custom application or use case using the Awesense Energy Transition Platform, or you have an analytical tool you would like us to demonstrate connecting with our Platform, please feel free to reach out at tools@awesense.com.